
谈起唐诗,人们往往先想到月下的乡愁、边塞的风雪、长安的春花与江南的夜雨。它们在千百年传诵中成为汉语审美的高峰,也成为中国人理解情感、山河与历史的重要方式。过去读诗,多从字句、意象、格律、流派、身世入手;今天,当大数据、人工智能、可视化技术进入古典文学研究,唐诗又多了一种新的打开方式:不只逐篇细读,也把浩瀚诗海作为可计算、可比较、可追踪的文化整体来观察。
所谓数字人文,并不是用机器替代人的阅读,更不是把诗意简化成一串数字。它的意义在于借助数据库、文本标注、自然语言处理、地理信息系统、统计模型等技术,帮助研究者在海量文献中发现以往不易察觉的结构、关联与变化。古典诗词研究尤其适合这种方法,因为它兼具文本规模大、体式规律强、历史信息密集等特点。以《全唐诗》为例,作品数量庞大,作者群体复杂,题材、声律、用典、地域、交游关系纵横交错,单靠人工翻检很难从整体层面描画其全貌。

近年来,清华大学有关团队围绕《全唐诗》开展声律数据库建设,正是数字人文进入古典诗歌核心问题的一项代表性工作。传统声律研究重在辨析平仄、押韵、对仗、句式等规则,强调诗歌声音结构与审美效果之间的关系。数据库方法则把这种研究推进到更大范围:通过对作品字词、句式、韵脚、平仄格式等信息进行结构化整理,研究者可以比较不同时期、不同体裁、不同作者在声律选择上的差异,观察近体诗成熟过程中的规律,也能检验一些长期依靠经验判断形成的文学史认识。
这种工作并不轻松。古典诗词的声律分析涉及中古音、今读音、异文、版本、诗体分类等问题,不能简单套用现代汉语读音。数据库建设的价值,正在于把复杂的校勘、标注与规则说明尽可能显性化,使后续研究有可复核的基础。换言之,数字化不是把古诗变成机械表格,而是把传统小学、音韵学、文献学与计算技术结合起来,为古典诗歌研究搭建一座更稳固的“脚手架”。

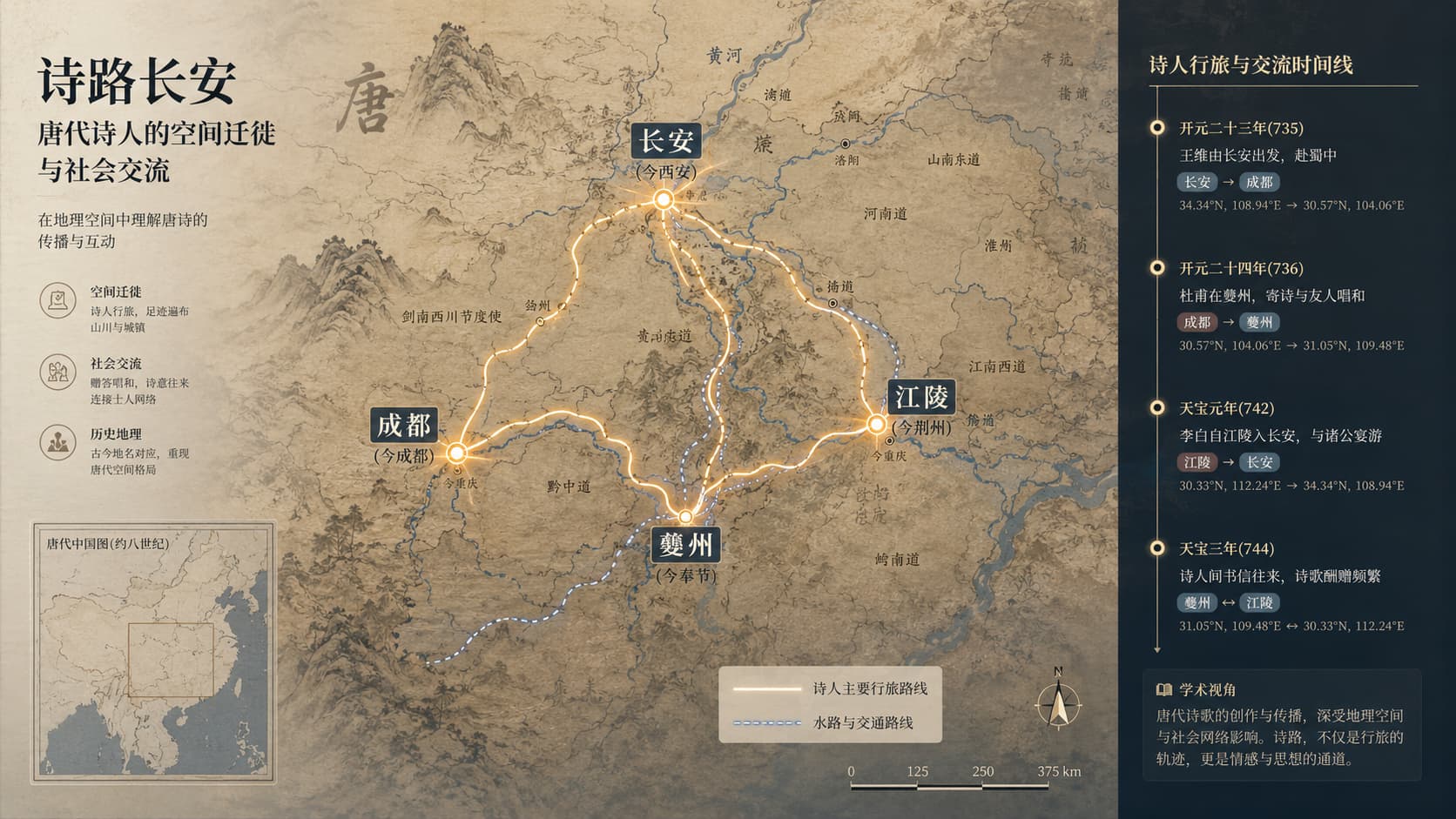
除了声音,空间与时间也是理解诗歌的重要坐标。唐宋文学编年地图等时空可视化项目,把诗人行迹、作品创作地点、历史年代、地名沿革等信息联系起来,让文学史不再只是一条朝代更替的线索,而是一幅可以展开的文化地图。读杜甫,人们可见其由长安到秦州、同谷、成都、夔州、江陵一带的漂泊轨迹;读王维、孟浩然,则能在山水与仕隐之间看到地域经验如何进入诗歌。地图不是给诗意画上边界,而是提醒我们:诗句背后有道路、驿站、江河、关塞,也有人的迁徙、交游与时代变动。
时空可视化的优势,在于把分散在诗题、序文、史传、年谱中的信息重新组织起来。传统文学史常说“盛唐气象”“中唐转折”“宋人以议论入诗”,这些概括当然有其理论价值;而数字地图可以进一步追问:某一类题材在何时何地集中出现?某些诗人群体的交往网络如何形成?政治中心、交通线路、山川名胜与诗歌生产之间是否存在可见关联?当这些问题被放到地图与时间轴上,文学史就获得了更立体的观察角度。
近年来,“嘉音常数”等量化分析思路也引起学界关注。它试图从诗歌结构、节奏与声音配置中提取可比较的指标,用以分析古典诗歌内部秩序。对于普通读者来说,这类概念听起来或许抽象,其实背后的问题很朴素:为什么有些诗读来圆转流美,有些诗显得峭拔顿挫?同样是五言或七言,为什么不同诗人的节奏感并不相同?如果把诗句的平仄、停顿、押韵位置、句间呼应等因素进行量化,是否能看出某种稳定的审美结构?
当然,任何量化指标都不能代替审美判断。诗歌之为诗,正在于语言、情感、历史处境与读者经验之间的微妙共振。数字模型可以揭示高频模式,却未必能解释一首诗为何动人;它能指出某种结构常见,却不能因此断定少见结构就没有价值。因此,面对“嘉音常数”一类研究,我们应把它看作新工具、新视角,而不是终极答案。它适合提出问题、辅助比较、暴露规律,也需要回到具体诗句中接受文学阐释的检验。
数字人文给古典诗词研究带来的改变,首先是尺度的改变。过去研究者常以名家名篇为中心,深入剖析代表性文本;今天则可以同时观察数万首作品,追踪词语、意象、格律、题材在长时段中的流动。例如“月”“江”“塞”“梦”“归”等常见意象,在不同时代和诗人笔下承担的情感功能并不完全相同。大规模统计能够帮助我们发现某些意象组合的兴衰变化,再由研究者结合社会史、思想史和文本细读作进一步解释。
其次是关系的改变。诗歌不是孤立生成的,它与作者身份、交游圈层、官职迁转、地域文化、书写传统密切相关。通过知识图谱和网络分析,研究者可以呈现诗人之间的唱和、赠答、师友、同僚关系,观察文学共同体如何形成。唐代诗人行卷、宴集、送别、题壁、唱和等活动,本来就是社会交往的一部分。数字技术把这些关系以网络形式呈现出来,有助于我们理解诗歌传播与文学声誉形成的机制。
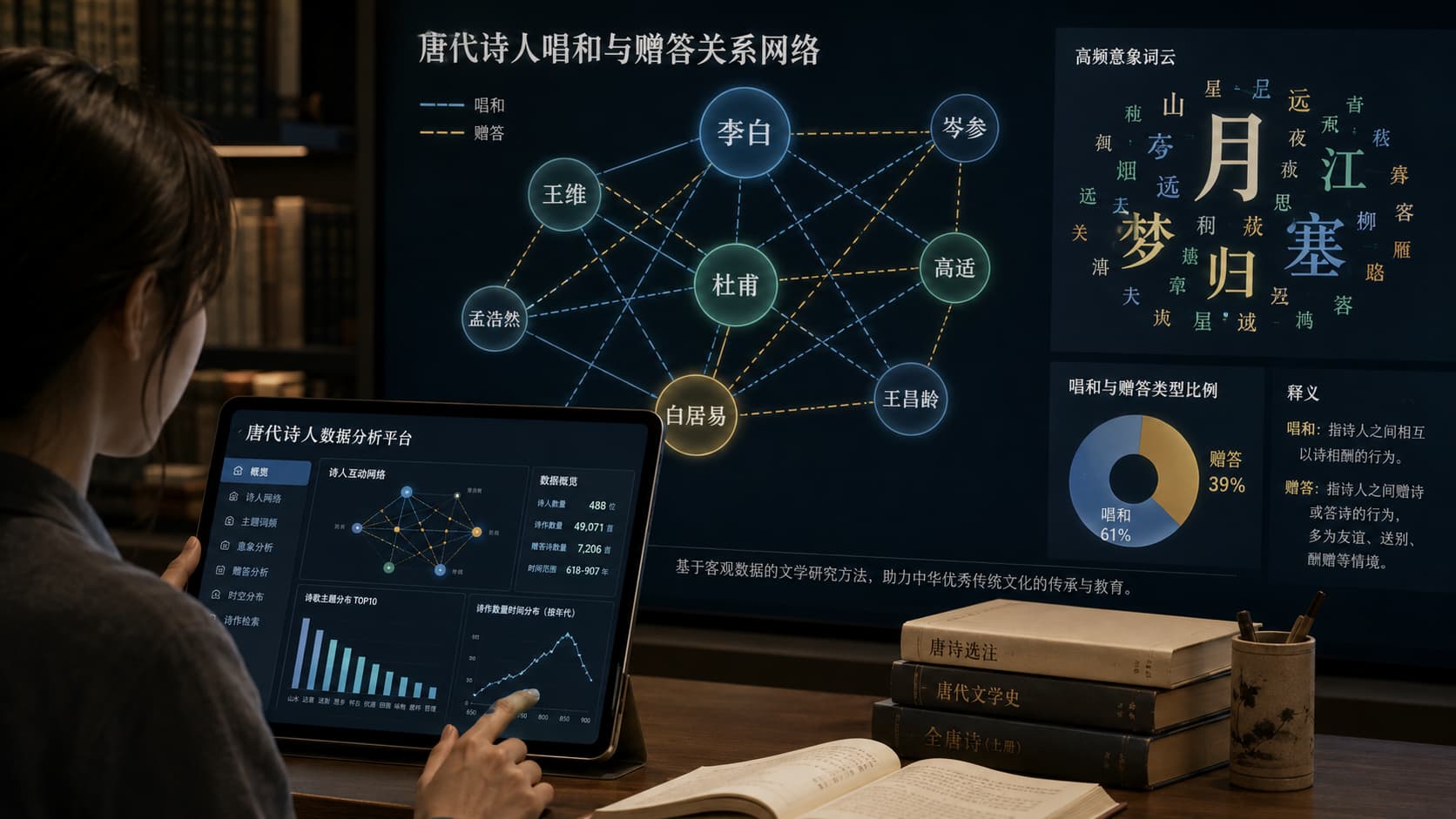
再次是阅读方式的改变。普通读者也可以从数字人文中获益。过去翻阅大型总集,容易被卷帙浩繁挡在门外;而检索、地图、可视化、词频分析等工具,能帮助读者从兴趣点进入诗歌世界。喜欢边塞诗,可以沿着河西、陇右、幽州等地理线索阅读;关注女性诗人,可以从作者群体和作品主题入手;想了解某个节气、某种花木、某条江河在诗中的形象,也可以通过数据库获得初步线索。技术在这里降低了进入门槛,却并不削弱经典的深度。
“熟读唐诗三百首,不会作诗也会吟。”这句流传甚广的话,强调的是反复涵泳的功夫。数字时代的阅读并不取消这种功夫,而是在“熟读”之外,增加了“通观”的能力。
大数据与人工智能也为古典诗词研究带来新的挑战。首先是数据质量问题。古籍整理涉及版本差异、文字讹误、作者归属、编年争议,若基础数据不可靠,后续分析越精巧,结论越可能偏离事实。其次是算法解释问题。模型可以给出相似度、聚类结果或生成摘要,但这些结果必须接受文献学和文学史常识的审视。再次是研究伦理问题。传统文化数字化应尊重原典,尊重学术规范,不能为了传播效果夸大结论,更不能把民俗、传说、术数等内容包装成未经证实的功效承诺。
因此,数字人文最理想的状态,是“算法有边界,阐释有根基”。研究者既要懂技术,也要敬畏文本;既要善用模型,也要保留对语言细节的敏感。李白诗中的“飞流直下三千尺”,不能只被看作夸张修辞的样本;杜甫诗中的“感时花溅泪,恨别鸟惊心”,也不能只被拆成情感词与自然意象的组合。数字分析可以告诉我们类似表达在诗歌史中的位置,却仍需人来体会其中的时代忧患与个体心声。
从更广阔的文化传播角度看,数字人文让古典诗词在当代获得新的公共表达。数据库、地图、交互平台、智能检索工具,把学术成果从书斋带到课堂、博物馆、网络空间和大众阅读场景中。它们让年轻读者看到,传统文化并不只是静态陈列的旧物,而是可以被重新整理、重新提问、重新理解的精神资源。当技术成为桥梁,古典文学便能以更亲近的方式进入今天的生活。
不过,越是在AI时代,越要明白“新读法”的重点不是追逐新奇,而是更准确、更深入地接近经典。大数据可以扩大视野,人工智能可以提高处理效率,可视化可以增强直观感受,但诗词研究最终仍要回到人的情感、语言与历史经验。唐诗之所以长久动人,不只是因为它拥有可计算的格律结构,更因为它把个体生命与时代气象、山河风物与人间情义凝结在精炼的汉语之中。
当大数据遇见唐诗,我们看到的不是冷冰冰的数字覆盖温热的诗心,而是古老文本在新工具照亮下显出新的纹理。数字人文像一盏侧光,让那些原本隐在浩瀚诗海中的联系、节奏与路径逐渐清晰。它提醒我们:传承中华优秀传统文化,既需要守正,也需要创新;既要尊重经典原貌,也要善用时代工具。如此,千年前的诗句才能在今天继续被阅读、被理解,并在新的知识图景中焕发持久的生命力。


